开源之夏2023申请书——优化CubeFS容器化部署
因为没确定的细节太多了,以及主要的精力放在了和 Mentor 沟通上。所以申请书写得很粗糙和仓促,后续有机会尽量再写个新版。
以下申请书正文:
一、课题背景与描述
1. CubeFS 简介
CubeFS是新一代云原生存储产品,目前是云原生计算基金会open in new window(CNCF)托管的孵化阶段开源项目, 兼容S3、POSIX、HDFS等多种访问协议,支持多副本与纠删码两种存储引擎,为用户提供多租户、 多AZ部署以及跨区域复制等多种特性,广泛应用于大数据、AI、容器平台、数据库、中间件存算分离、数据共享以及数据保护等场景。
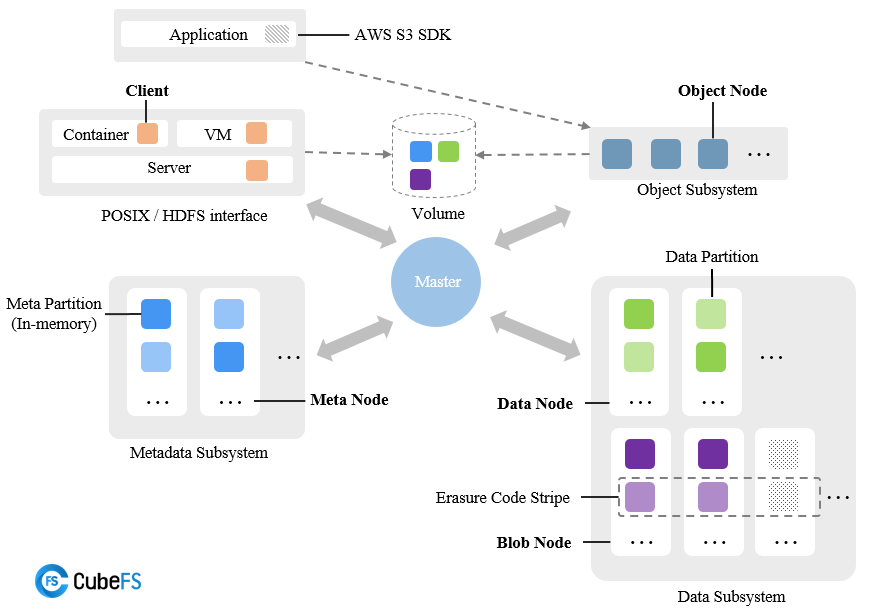
CubeFS由 元数据子系统(Metadata Subsystem) ,数据子系统(Data Subsystem) 和 资源管理节点(Master) 以及 对象网关(Object Subsystem) 组成,可以通过POSIX/HDFS/S3接口访问存储数据。
上面的介绍与架构图来自 CubeFS 官方文档 ,下面我将针对性地介绍与本课题相关的内容。
CubeFS 是一个经典的解耦架构,每个组件都有若干个实例构成,各组件支持水平拓展。
- 资源管理节点:由多个 Master 节点组成。负责异步处理不同类型的任务。Master 之间通过 raft 协议实现分布式一致性,启动时每个 Master 需要配置其他 raft 复制成员组信息。
- 元数据子系统:由多个Meta Node节点组成,负责记录元数据。每个 Meta Node 启动时都指定了 Master 集群的地址信息,用于主动向 Master 注册信息。
- 数据子系统:分为副本子系统(DataNode)和纠删码子系统(本课题暂不涉及),负责存储数据。类似于 MetaNode,启动时需要指定 Master 集群地址。
- 对象子系统:可以理解为基于数据子系统,提供了兼容标准S3语义的访问协议。
其中,每个组件的每个节点启动时都需要传入一个 json 配置文件。
CubeFS 还有可用区(Zone)与 NodeSet 的概念:一个 Cluster 由多个 Zone组成,每个 Zone 含有多个NodeSet,每个 NodeSet下含有多个 MetaNode 与 DataNode。
2. 本次课题简介
1. OSPP(开源之夏)课题介绍
简介:
当前CubeFS容器化部署采用的是个bash脚本,功能比较单一,只支持一键部署和清理。不支持集群拓扑的修改,单个服务/角色升级,一键升级及扩容,集群运维管理等。
项目需要使用Go语言进行容器化部署重构,支持根据拓扑文件容器化部署集群,支持一键升级和扩容等功能。
相关Issue:https://github.com/cubefs/cubefs/issues/1927
2. 项目定位补充
经过与导师的多次线上文字、语音沟通请教,我弄清了课题的更多细节(主要是项目定位):
CubeFS 其实已经有了 Helm 部署方案 ,既支持部署 CubeFS 本身,也支持将 CubeFS 作为 CSI 插件部署在 Kubernetes 中。但 Kubernetes 使用相对复杂,为了让更多的人快速体验 CubeFS 以扩大社区影响力,推出了分布式的容器化部署。
本项目主要适用场景是:①运维人员快速体验②无 Kubernetes 下的生产环境部署③开发测试
二、总体设计
因详细设计容易发生变动,所以本申请书不会涉及太多的技术细节,主要是总体模块的设计,以及一些核心的关键点的处理。
在明确了需要做哪些模块,每个模块之间沟通的接口(数据结构)如何,具体的内部细节可以在开发的过程中随时调整。
代码相关的设计细节,请直接查阅 aFlyBird0/cubefsadm 仓库,不断更新中。目前已经完成了部分概念验证(Proof of Concept)。
1. 产品最终效果
课题产出物名字暂拟为 CubeFS-Adm(忽略大小写)。
介绍一下用户如何去使用 CubeFS-Adm:
首先形态是一个 CLI,拥有两个核心配置文件,一个配置是主机列表(ssh信息等),另一个配置是集群拓扑配置(MetaNode、DataNode等),后者会引用前者的主机信息。
- 对集群的任何 “写”(扩容、更新、删除等)操作,都是一个
apply命令,附上最新的期望的集群拓扑配置,adm 会自动计算出需要的变更,然后执行。 - 对集群的读操作,也是一个核心的命令。名字可能是
getlistread等。
2. 主要模块构成
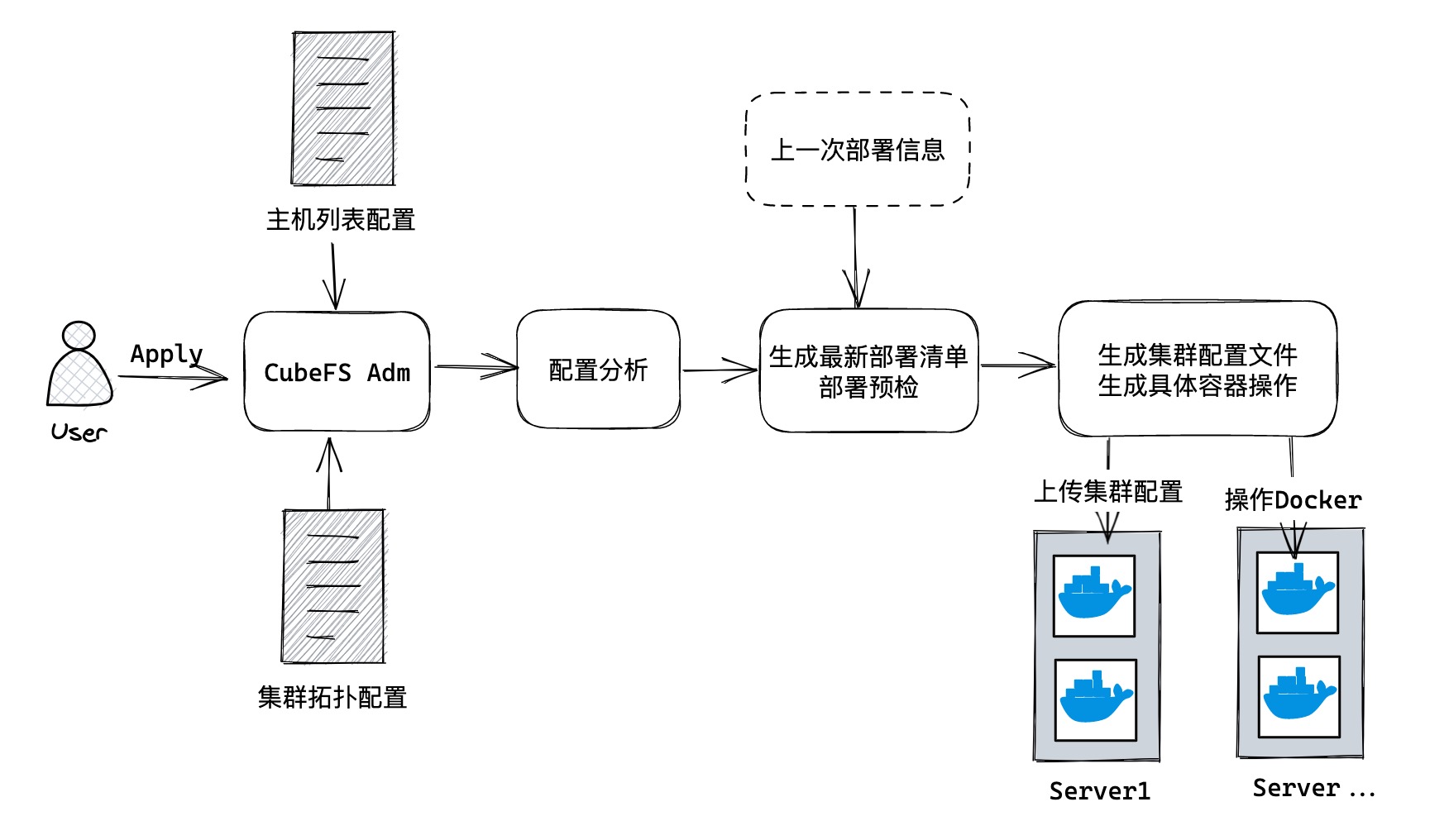
用户使用 CubeFS Adm 的主要流程如下:
- 填写配置:填写主机列表配置,配置主机的 SSH 访问信息;填写集群拓扑配置信息。
- 执行
apply命令:指定两个配置文件的地址(配置文件地址可设默认值)即可。后面所有的内容都由 CLI 完成。 - 配置分析:程序根据两个配置文件,生成最终的详细的集群的 Go 结构体信息。主要涉及以下内容:
- 解析自定义的简化版配置。为了方便用户填写配置文件,尽可能避免配置冗余的情况,我们需要设置一些语法糖,包含快速设置副本数,自动为每个机器顺序分配端口等等。
- 默认值的注入。大部分配置我们都是设置了
- 非直接配置项的生成。有些配置项不应直接交由用户设置,比如当所有master的部署情况确定后,DataNode 的
masterAddr配置项也就自动计算出来了。 - 配置初步检查。对配置本身进行检查,比如格式、比如 Master 的数量是否达到要求等。
- 比对上一次部署信息,生成最新部署清单
- 每次
apply成功后,系统都会生成一份本次操作的集群拓扑信息,用于与下一次apply时进行比较。 - 比较上一次的拓扑信息和最新的期望的拓扑信息,程序就可以计算出需要执行的操作。比如 DataNode 多了一个,就执行扩容,新增一个节点。(实际上会更复杂,例如对 Master 做了改动,会影响到 DataNode 等节点)
- 生成的部署清单包含了 Docker 相关信息,也包含了每个组件的启动配置文件。
- 部署预检。上一步检查是对配置本身,这步的检查会涉及到集群本身的状态,例如选择的端口当前机器是否已占用等等。
- 每次
- 上传集群配置,操作 Docker
- 将每个组件的启动配置文件,分发到对应的主机上
- 执行 Docker 操作
三、详细设计
3.1 配置相关设计
主要分为主机列表配置和集群拓扑配置。
3.1.1 主机列表配置
主要是配置
- SSH 连接信息,机器名(为了在集群拓扑配置中引用)
- 机器所属的 Zone 和 NodeSet。
1. SSH 连接信息
不做过多赘述,参考 SSH Config 的结构,做一些定制化即可。
设置一些公有配置即可,类似于对 Host * 的支持。比如设置默认的私钥地址是 xxx,个别机器特殊可覆盖此配置项。
2. Zone 与 NodeSet
这块是 CubeFS 的独特之处,每个组件都属于特定的 Zone 和 NodeSet。
考虑到 Zone 和 NodeSet 本身就是用于灾备属性的,所以我们没有必要去支持每个容器设置 Zone 与 NodeSet。如果出现网络等外部问题,大概率是以机器为单位出现故障(虚拟机也是一样的,一台虚拟机可以视为一台独立的物理机)。
所以我们直接将 Zone 与 NodeSet 和机器本身绑定。
最终的配置示意
(只是示意,具体字段在正式版发布前可随时调整)
global:
port: 22
user: root
keyFile: ~/.ssh/id_rsa
zones:
- zoneName: zone1
nodesets:
- nodesetName: nodeset1
hosts:
- host: host1
hostname: 1.2.3.4
- host: host2
hostname: 1.2.3.5
port: 12222
- nodesetName: nodeset2
hosts:
- host: host3
hostname: 1.2.4.4
可以看到:
- 可以设置
global属性,为所有主机设置默认配置值,也可以覆盖。(如果有必要。甚至可以支持设置 zone 级别和 nodeset 级别的默认值) - 配置文件中存在多个 zone,每个 zone 由多个 nodeset 组成,每个 nodeset 下又有多个主机组成。(实际每个 nodeset 与 zone 主机数会多很多,这里只是为了演示)
为什么选用上面这种方案
其实还有一种设计方式,所有的 Host 扁平,在每个 Host 中设置 zone 和 nodeset 字段,大概这样:
hosts:
- host: host1
hostname: 1.2.3.4
zone: default
nodeset: nodeset1
- host: host2
hostname: 1.2.3.5
port: 12222
zone: default
nodeset: nodeset2
这种配置设计方式有以下几个弊端:
- 当机器数变多的时候,每个主机的 zone 和 nodeset 必须都要设置,占两行空间。即使加了默认值的逻辑,也只有在 zone 和 nodeset 数都为1的时候才方便。
- 没有强制将同一 zone,同一 nodeset 的主机写到一起。如果用户使用这样的配置方式,在新增主机的时候,可能会选择每次都将新主机插入到最下面,导致同一 zone、nodeset 的主机散落在配置文件的不同位置,非常难以管理。
3.1.2 集群拓扑配置
3.1.2.1 程序期待的配置
meta_nodes:
deploy:
- config:
listen: 17210
host: server-host1
- config:
listen: 17211
host: server-host2
data_nodes:
...
上面是一个极简的程序期待的拓扑配置文件:
- 一级 key 指定了服务的类型,包含了 MetaNode、Master、DataNode 等各种组件类型。
- 每种组件拥有一个
deploy配置信息,内部是一个数组,每个元素包含了两个字段host:指定了部署的主机(主机名在主机列表配置中定义)config:该节点的详细配置信息,如监听 IP、日志级别等等。
程序可以直接定义一个 Go 结构体,把这个配置文件直接反序列化了。然后再通过综合分析所有的配置,生成每个节点容器部署所需的真正的 JSON 配置文件(见官方文档-服务配置介绍)与 Docker 参数。
3.1.2.2 简化用户填写的配置(语法糖)
上面的配置只是最简单的例子,实际上每个节点都有非常多的配置项,以及当节点数暴涨后配置会非常繁杂。
所以我们需要定义一些特殊语法,支持简化的配置(可以理解为语法糖)。
所以配置解析部分的一大重点也在于,如何设计简化语法,如何将简化的配置文件渲染成程序期待的详尽的配置文件。
本申请书不提过多的实现细节,仅介绍有哪些简化语法的方式(参考 curveadm)
- 层级:类似于 SSH 的公共配置的概念,我们可以将
meta_nodes下建立一个与deploy同级的配置项,key 为config,用来配置该组件类型的所有节点的默认配置。 - 变量/函数:有时我们希望为不同的节点设置类似但会自动改变的属性。例如设置一个变量,会自动替换成主机ip;设置一个自增函数,传入一个初始值,在相同的机器上该函数的返回值会自增(以实现端口自动累加)。值得一提的是,我们结合层级与变量,可以极大地简化配置。例如我们可以通过层级设置所有节点的监听ip为
主机ip变量。 - replica:在
config与host同级属性下,新增一个replica属性,以实现同一个主机下快速部署多个容器。
注:对于配置简化的设计细节,我在 POC 中已经给出了一个基于 Go Template 的基本方案,可以前往查看更多细节。(后续可能会采用 POC 的方式,也可能会采用 curveadm 的基于正则的方式。但二者对后续的模块都不会有影响,因为最终生成的都是程序期望的配置文件,或者说详尽的 Go 结构体)
3.2 生成部署清单与容器操作
CubeFS Adm 吸取了 Kubernetes 的声明式的核心思想:
- 用户不指定要做什么具体的操作,只是声明最终期望的集群拓扑状态
- 一切以配置文件为准
(不过还是有很大的区别,因为这本质上是个 CLI 程序,所以没有后台运行的调协逻辑,而是在用户每次执行 apply 命令的时候,进行分析。)
下面是简单的解释:
- 如果用户想新增一个
DataNode,只需要改动一下集群拓扑配置,加入一个新 Host 或者把某个 Host 的 replica 加1即可。然后apply。删除同理。 - 如果用户想升级
MetaNode的容器镜像版本,也是修改配置文件的对应字段,apply。
所以这个模块的难点在于:比对前一次部署的拓扑配置和最新的期望的拓扑配置声明,计算出具体的容器操作。
3.2.1 diff 集群拓扑配置
这部分相对好做:
- 每次
apply成功后,存一份完整的拓扑配置信息 - 用户再次
apply,将简化的配置解析成程序期待的完整的突破配置信息 - 至此两份拓扑配置结构完全一致,使用相同的解析方法,反序列化成结构体。实现 Diff 逻辑即可,分析出哪些角色组发生了变化,以及变化的类型。
3.2.2 计算具体容器操作
这部分会有很多复杂的情况:
1. 不影响其他节点的操作
当我们执行新增一个 DataNode,或修改 MetaNode 的镜像版本等操作时。只需要新建/删除/重启某个具体的容器,不需要操作其他容器
2. 影响相同角色节点的操作
有时候我们对某个角色的某个容器进行了操作,它会导致其他相同角色的所有节点都需要更新。
3. 影响不同角色节点的操作
如 Master 扩容后,MetaNode、DataNode 等节点需要重载配置,以注册到新的 Master 集合。(好在和 Mentor 沟通后,了解到一般 Master 不太会扩容。这种最复杂的情况发生频率并不高
一些其他因素
- 同时还涉及到 Zone、NodeSet 的因素。
- 以及需要考虑容器的更新顺序,防止更新过快导致可用副本数过少(类似于 Kubernetes 滚动更新时的一些参数设置),不过初版可以先实现串行顺序更新。
- 节点更新时是否需要主动处理 CubeFS 的数据迁移,还是 CubeFS 本身会自行处理。
下面主要讲讲如何处理前面提到的依赖影响关系:
我设计了几个基本的概念,来更为结构化地去解决这个问题:
- 原子操作:
- 对某个节点上的某个特定服务(容器)进行的特定操作。
- 原子操作目前只有 创建、删除、修改并重启 三种。
- 角色组操作:
- 对某个角色组的所有实例进行的操作。例如 DataNode 分别在 5 个机器上共部署了 10 个实例,那么这些实例组成了一个 DataNode 角色组。
- 角色组的操作,本质上是对每个实例进行原子操作的按序执行。
- 影响传递
- 某个角色组造成的影响,会传递到其他角色组。例如 master 组发生了扩容、缩容操作,会影响到几乎其他所有角色组的变更。(master修改并重启并不会影响其他角色组)
- 通过类似 DAG(有向无环图)的方式,来描述影响传递的关系。描述方式大概是:「A角色组的扩容、缩容操作 -> B角色组的修改并重启操作」
- 影响图中,并不需要定义如何去影响,只需要起到告知被影响方需要做出响应的动作即可。因为在用户执行 apply 命令时,我们已经能根据最新的集群拓扑文件,知道每个角色组有哪些实例,以及每个实例的最新的配置文件。
- A角色组发生的变化,只会通知到整个B角色组(不会直接通知到实例),由角色组内部负责对每个实例进行必要的原子操作。
通过以上的基本设计,我们能复杂的集群拓扑变更信息,转化为一张 DAG 影响图,然后从入度为0的节点,依次执行操作即可。
注:在 POC 中有更为详细的描述、举例、细节。
3.3 Docker 容器操作
最后一步就是将使用 Go 实现 SSH 登录主机与操作容器。
但这里存在着很大的问题:
当我们想在程序中操控远程的容器的时候,可能会想到以下两种方式:
- 开启 Docker 的远程访问,使用 Docker 的 Go SDK 访问
- 使用 Go 通过 SSH 登录远程机器,然后通过 Docker CLI 访问
前者需要重启 Docker Daemon;后者需要自行拼接 Docker CLI 命令以及使用正则解析命令行输出,非常难受。
本项目提出了一种基于 SSH 转发 socket 从而达到不开启 Docker 远程访问也能使用 Go SDK 操作 Docker 的方式,详见 aFlyBird0/ssh-container 。
四、开发计划
| 时间 | 计划 |
|---|---|
| 06.26-07.15 | 细化POC;确定各部分实现细节 |
| 07.16-08.15 | 实现MVP版本;预留后续优化接口 |
| 08.16-08.31 | 增加特性,实现完美状态下可运行的版本 |
| 09.01-09.15 | 增加异常情况处理逻辑;测试;与社区沟通,完善细节 |
| 09.16-09.31 | 撰写使用文档;准备结项报告 |